三步搞定数据统计分析 从处理、分析到可视化
在当今数据驱动的时代,高效地进行数据统计分析已成为众多领域的核心技能。无论是商业决策、学术研究还是日常运营,掌握一套清晰、高效的流程至关重要。本文将为您梳理一个精简而强大的三步法:数据处理、统计分析、结果可视化,助您轻松驾驭数据,挖掘深层价值。
第一步:数据处理——夯实分析基础
数据处理是整个统计分析流程的基石,其质量直接决定后续分析的可靠性与有效性。此阶段的核心目标是获取干净、规整、可用于分析的数据集。
- 数据收集与导入:根据分析目标,从数据库、API接口、电子表格或调查问卷等多种渠道收集原始数据,并将其导入到专业的分析工具(如Python的Pandas库、R语言、Excel或SPSS)中。
- 数据清洗:这是最关键的一环。需要处理缺失值(如删除、填充)、纠正错误值、识别并处理异常值,并确保数据格式的统一(例如,日期格式标准化、文本编码一致)。
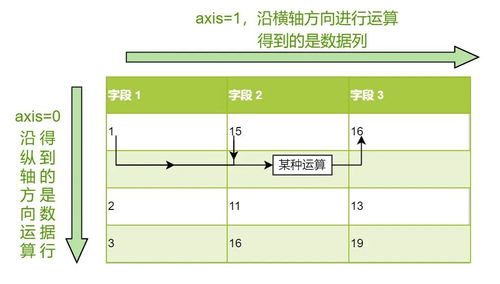
- 数据整理与转换:对数据进行重构,使其符合分析需求。包括创建新的计算字段(如计算比率、增长率)、数据分组(分箱)、以及将数据从“宽格式”转换为更适合分析的“长格式”等。
核心要义:宁可在数据准备阶段多花时间,也绝不让“垃圾数据”进入分析流程,正所谓“Garbage in, garbage out”。
第二步:统计分析——洞察数据内在规律
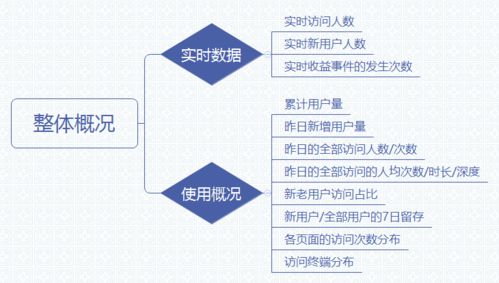
在坚实的数据基础上,运用统计方法探索数据特征、检验假设并发现规律。此阶段是从“数据”到“信息”的关键转化。
- 描述性统计分析:首先对数据进行整体描述。计算核心指标,如均值、中位数、众数(集中趋势)、标准差、方差、极差(离散程度),以及通过分位数了解数据分布。制作频数表、交叉表也是常见方法。
- 探索性数据分析:通过图形化方法(如箱线图、直方图、散点图矩阵)直观探索变量分布、关系及异常点,形成初步假设。
- 推断性统计分析:基于样本数据推断总体特征。常用方法包括:
- 参数检验:如t检验(比较两组均值)、方差分析(比较多组均值)、相关分析与回归分析(探究变量间关系)。
- 非参数检验:当数据不满足参数检验假设时使用,如曼-惠特尼U检验、卡方检验等。
- 模型构建与验证:对于更复杂的预测或解释性问题,可能会建立统计模型(如线性回归、逻辑回归、时间序列模型),并利用训练集/测试集等方法验证模型效果。
核心要义:根据具体业务问题和数据特征,选择合适的统计方法,避免误用。理解每个检验的前提假设和结果的实际意义比单纯运行软件更重要。
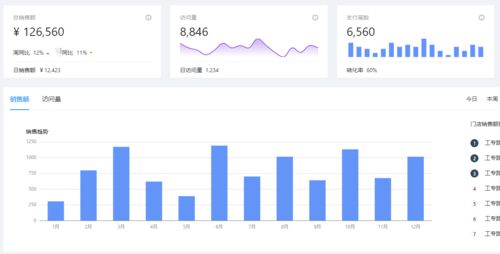
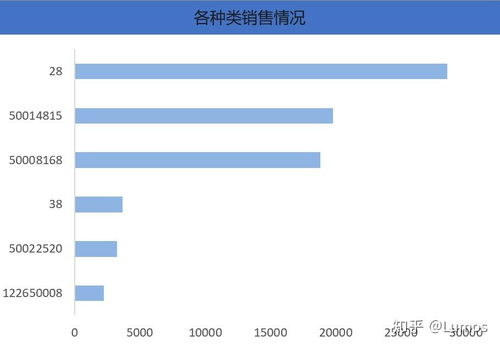
第三步:结果可视化——呈现洞察与驱动决策
分析得出的数字和结论需要通过直观、易懂的方式呈现出来,才能有效沟通洞察,支持决策。可视化是连接分析与行动的桥梁。
- 选择正确的图表:
- 比较:条形图、柱状图。
- 构成:饼图(仅限少数类别)、堆叠柱状图、瀑布图。
- 分布:直方图、箱线图、密度图。
- 关系:散点图、气泡图、热力图。
- 趋势:折线图、面积图(时间序列)。
- 遵循可视化最佳实践:
- 简洁清晰:避免图表垃圾,如不必要的3D效果、过度装饰。
- 准确标注:确保坐标轴、图例、标题清晰无误。
- 突出重点:使用颜色、大小、标注等方式引导观众关注关键信息。
- 讲述故事:将多个图表按逻辑顺序组织,形成一份连贯的数据分析报告或仪表板,阐述从发现问题到得出结论的全过程。
- 利用现代工具:借助Tableau、Power BI、Matplotlib、Seaborn、ggplot2等强大的可视化工具或库,可以高效创建出兼具美观与功能性的图表和交互式仪表板。
核心要义:可视化的目标不是展示所有数据,而是高效传达最重要的发现。一张优秀的图表应能让人在几秒钟内理解核心信息。
循环迭代,持续优化
“处理-分析-可视化”这三步并非严格的一次性线性流程,而往往是一个循环迭代的过程。在可视化阶段可能会发现新的问题或异常,需要返回数据处理阶段进行核查;初步分析结论也可能促使我们收集新的数据或进行更深入的统计检验。
掌握这个三步框架,并辅以合适的工具(如Python生态中的Pandas、NumPy、SciPy、Matplotlib/Seaborn,或R语言中的tidyverse系列包),您就能系统性地应对大多数数据统计分析任务,将原始数据转化为清晰的见解和有力的行动指南,真正实现数据价值的落地。
如若转载,请注明出处:http://www.iata-boms.com/product/65.html
更新时间:2026-04-15 16:02:44