Kubernetes 在数据分析与处理中的应用与优势
一、Kubernetes 简介
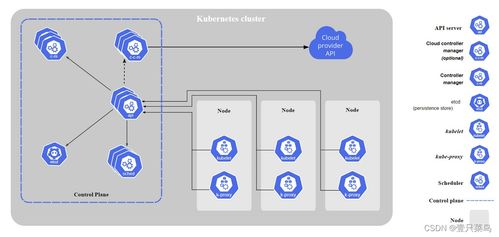
Kubernetes(通常简称为 K8s)是一个开源的容器编排平台,由 Google 设计并捐赠给 Cloud Native Computing Foundation(CNCF)。它旨在自动化容器化应用的部署、扩展和管理。通过 Kubernetes,用户可以高效地管理分布式系统,确保应用的高可用性、弹性伸缩以及资源优化。
Kubernetes 的核心概念包括 Pod(最小的部署单元,可包含一个或多个容器)、Service(提供稳定的网络端点)、Deployment(管理应用的生命周期)和 Namespace(用于资源隔离)。这些功能使 Kubernetes 成为现代云原生应用的首选平台。
二、Kubernetes 在数据分析与处理中的角色
在数据分析与处理领域,Kubernetes 提供了强大的支持,尤其适用于大数据处理、机器学习工作流和实时数据处理等场景。以下是其主要应用:
- 弹性伸缩与资源管理:数据分析任务通常需要大量计算资源,但负载可能波动较大。Kubernetes 的自动伸缩功能(如 Horizontal Pod Autoscaler)可以根据 CPU 或内存使用率动态调整 Pod 数量,确保资源高效利用,同时降低成本。
- 工作流编排:对于复杂的数据处理管道(如 ETL 流程或机器学习模型训练),Kubernetes 可以协调多个组件(如 Spark、Flink 或 Airflow),通过声明式配置确保任务按顺序执行,并处理故障恢复。
- 高可用性与容错性:数据分析系统往往要求 24/7 运行。Kubernetes 通过副本集和健康检查机制,自动重启失败的容器或重新调度 Pod,提高系统的可靠性。
- 多环境一致性:Kubernetes 支持在本地、云或混合环境中部署数据分析应用,确保开发、测试和生产环境的一致性,简化了数据流水线的迁移和维护。
三、实际案例与工具集成
许多流行的数据分析框架已与 Kubernetes 深度集成。例如:
- Apache Spark:通过 Kubernetes 原生支持,Spark 作业可以直接在 K8s 集群上运行,实现资源的动态分配。
- Kubeflow:一个基于 Kubernetes 的机器学习平台,帮助用户构建端到端的 ML 工作流,包括数据预处理、模型训练和部署。
- Prometheus 与 Grafana:这些监控工具可与 Kubernetes 结合,实时跟踪数据处理任务的性能和资源使用情况。
四、总结
Kubernetes 不仅简化了容器化应用的管理,还为数据分析与处理提供了灵活、可扩展的基础设施。通过自动化部署、弹性伸缩和容错机制,它显著提升了数据团队的效率,并支持从批处理到实时分析的多样化需求。随着云原生技术的普及,Kubernetes 在数据领域的应用将更加广泛,成为现代数据架构的核心组成部分。
如若转载,请注明出处:http://www.iata-boms.com/product/31.html
更新时间:2025-11-28 20:00:02